intro
[-1. Implementing and refactoring neural networks for language modeling
]Continuing makemore implementation with multilayer perceptron for character-level language modeling, planning to move to larger neural networks.
]Understanding neural net activations and gradients in training is crucial for optimizing architectures.
starter code
-[-11,000 parameters over 200,000 steps, achieving train and val loss of 2.16.
]Refactored code to optimize neural net with
[-2. Efficiency of torch.no_grad and neural net initialization issues
]Using torch.nograd decorator to prevent gradients computation.
]Using torch's no_grad makes computation more efficient by eliminating gradient tracking.
fixing the initial loss
-[-27, rapidly decreases to 1 or 2.
- Initial loss (): High initial loss (e.g., 27) indicates improper network initialization.- Softmax logits should be close to zero at initialization to produce a uniform probability distribution and expected loss.- This avoids confident mispredictions and the "hockey stick" loss curve.
]Network initialization causes high loss of
-[-27 characters, with roughly 1/27 probability for each.
]At initialization, the model aims for a uniform distribution among
Hi Andrej, Thank you for the amazing set of lectures which elucidate multiple aspects of training a ML model. In the video you mention that at the beginning of training, we expect the NN to have all equal probabilities I.e. 1/27 which implies that all logins should be close to 0. Using this logic you arrive at the fact that weight matrices should be initialized close to 0. How does one think about this for regression problems like autoencoders? What would a “good” starting output be? Is it still all zeros?
]Neural net creates skewed probability distributions leading to high loss.
At , it's a bit subtle why it's called a loss because it's not immediately apparent with respect to what it is a loss. It seems it's the loss resulting from choosing the character having index i given the probability distribution stored in the tensor.
- Scaling down weights of the output layer can achieve this ().
-[-2.12-2.16
]Loss at initialization as expected, improved to
fixing the saturated tanh
- Saturated activations (): Tanh activations clustered around -1 and 1 indicate saturation, hindering gradient flow.- Saturated neurons update less frequently and impede training.
[-3. Neural network initialization
the night and day shift
not only sweating but also loosing hair :)
Andrej's transformation between and
so, no one is going to talk about how andrej grew a decade younger 🤔
was pretty quick 😉
-[-1 or 1, leading to a halt in back propagation.
]The chain rule with local gradient is affected when outputs of tanh are close to -
]Concern over destructive gradients in flat regions of h outputs, tackled by analyzing absolute values.
- This can lead to dead neurons, which never activate and don't learn ().
- Scaling down weights of the hidden layer can help prevent saturation ().
@Andrej Karpathy Great video! A quick question: at Why a U shape is better than a Cup shape for the histogram of h? Don't we want h to be have some normal distribution, like hpreact?
-[-2.17 to 2.10 by fixing softmax and 10-inch layer issues.
]Optimization led to improved validation loss from
calculating the init scale: “Kaiming init”
- Kaiming initialization (): A principled approach to weight scaling, aiming for unit gaussian activations throughout the network.
]Standard deviation expanded to three, aiming for unit gaussian distribution in neural nets.
-[-0.2 shrinks gaussian with standard deviation 0.6.
]Scaling down by
- Calculates standard deviation based on fan-in and gain factor specific to the non-linearity used ().
]Initializing neural network weights for well-behaved activations, kaiming he et al.
- PyTorch offers torch.nn.init.kaiming_normal_ for this ().
modern inovations that makes things stable and that makes us not be super detailed and careful with the gradient and backprop issues. (self-note)
[-4. Neural net initialization and batch normalization
]Modern innovations have improved network stability and behavior, including residual connections, normalization layers, and better optimizers.
]Modern innovations like normalization layers and better optimizers reduce the need for precise neural net initialization.
The standard deviation relation used to rescale the inital weights, will this only work in the case that the input data also has variance approximately 1 right?
batch normalization
*Batch Normalization (****):*- Concept: Normalizes activations within each batch to be roughly unit gaussian.- Controls activation scale, stabilizing training and mitigating the need for precise weight initialization.
-[-2015 enabled reliable training of deep neural nets.
]Batch normalization from
]Standardizing hidden states to be unit gaussian is a perfectly differentiable operation, a key insight in the paper.
- Implementation ():
- Normalizes activations by subtracting batch mean and dividing by batch standard deviation ().
]Batch normalization enables reliable training of deep neural nets, ensuring roughly gaussian hidden states for improved performance.
]Calculating standard deviation of activations, mean is average value of neuron's activation.
std should be a centralized moment (i.e. subtract the mean first) according to the paper although I see that PyTorch imp is the same as yours
Around , wouldn't adding scale and shift revert the previous normalization? Improper scale and shift parameters will still cause activation saturated.
Just to be clear, normalising the pre-activation neurons to have 0 mean and 1 std does not make them Gaussian distributed. The sum is only Gaussian distributed at initialisation, because we have initialised the weights to be normally distributed.
- Learnable gain and bias parameters allow the network to adjust the normalized distribution ().
]Back propagation guides distribution movement, adding scale and shift for final output
- Couples examples within a batch, leading to potential bugs and inconsistencies ().
Can anyone explain what he has said from to
[-5. Jittering and batch normalization in neural network training
- Offers a regularization effect due to coupling examples within a batch ().
]Padding input examples adds entropy, augments data, and regularizes neural nets.
?
- Requires careful handling at inference time due to batch dependency ().
]Batch normalization effectively controls activations and their distributions.
- Running mean and variance are tracked during training and used for inference ().- Caveats:
]Batch normalization paper introduces running mean and standard deviation estimation during training.
@Andrej Karpathy At , bnmean_running = (0.999 * bnmean_running) + (0.001 * bnmeani), why are you multiplying 0.999 with bnmean_running and 0.001 with bnmeani. Why this not works *bnmean_running = bnmean_running + bnmeani*
is basically an Infinite Impulse Response (IIR) filter
Can any one please tell that at , why did we take the numbers 0.999 and 0.001 specifically? I am new to neural networks and all of this is a bit overwhelming. Thanks
]Eliminated explicit calibration stage, almost done with batch normalization, epsilon prevents division by zero.
[-6. Batch normalization and resnet in pytorch
- Makes bias terms in preceding layers redundant ().
I can't understand why removing the mean removes the effect of adding a bias? Why would the grad be zero?
]Biases are subtracted out in batch normalization, reducing their impact to zero.
batch normalization: summary
]Using batch normalization to control activations in neural net, with gain, bias, mean, and standard deviation parameters.
At would it help at the end of the training to optimize with bnmean_running and bnstd_running to normalize the preactivations hpreact? Maybe at that point regularization isn't necessary anymore and the rest of the weights can be optimized for the particular batch norm calibration that will be used during inference.
real example: resnet50 walkthrough
also I would add that ReLU is much easier to compute (max of 2 values and derivative is eighter 0 or 1) than tanh where we have exponents
]Creating deep neural networks with weight layers, normalization, and non-linearity, as exemplified in the provided code.
- Default PyTorch initialization schemes and parameters are discussed ().
[-7. Pytorch weight initialization and batch normalization
-[-1/fan-in square root from a uniform distribution.
Great video, I loved it. Just a question. In the Linear layer on PyTorch at , he says that to initialise the weights the uniform distribution is used, but then in the implementation of the Linear layer when PyTorch-ifying the code he uses the Normal distribution. Did I loose something or he committed a "mistake" ?
]Pytorch initializes weights using
reason they're doing this is if you have a roughly gsan input this will ensure that out of this layer you will have a
roughly Gan output and you you basically achieve that by scaling the weights by
-[-1 over sqrt of fan in, using batch normalization layer in pytorch with 200 features.
]Scaling weights by
summary of the lecture
]Importance of understanding activations and gradients in neural networks, especially as they get bigger and deeper.
]Batch normalization centers data for gaussian activations in deep neural networks.
-[-2015, enabled reliable training of much deeper neural nets.
]Batch normalization, influential in
He says 'Bye', but looking at the time, it seems too early []. Most people don't want lectures to be long, but I'm happy this one didn't end there.
just kidding: part2: PyTorch-ifying the code
always gets me
The "Okay, so I lied" moment was too relatable xD
*PyTorch-ifying the code (****):*
I don't understand where the layers are organized by putting a tanh after each linear layer while the initialization of the linear layer is `self.weight = torch.randn((fan_in, fan_out), generator=g) / fan_in**0.5`. I think it's not Kaiming initialization, because the gain for tanh is `5/3`, but in the code it's set to `1`,
*Diagnostic Tools (****):*
- Code is restructured using torch.nn.Module subclasses for linear, batch normalization, and tanh layers ().- This modular approach aligns with PyTorch's structure and allows easy stacking of layers.
[-8. Custom pytorch layer and network analysis
]Updating buffers using exponential moving average with torch.nograd context manager.
Why is the last layer made "less confident like we saw" and where did we see this?
-[-46,000 parameters and uses pytorch for forward and backward passes, with visualizations of forward pass activations.
@ I'd use emb.flatten(1, 2) instead of emb.view(emb.shape[0], -1) to combine two last dimensions into one. It feels that it is better to avoid shape lookup - emb.shape[0]
viz #1: forward pass activations statistics
- Forward pass activations: Should exhibit a stable distribution across layers, indicating proper scaling ().
- Visualization of statistics: Histograms of activations, gradients, weights, and update:data ratios reveal potential issues during training ().
]The model has
-[-20% initially, then stabilizes at 5% with a standard deviation of 0.65 due to gain set at 5 over 3.
]Saturation stabilizes at
? Anyone please explain at
Around the mark, I think I missed why some saturation (around 5%) is better than no saturation at all. Didn't saturation impede further training? Perhaps he just meant that 5% is low enough, and that's the best we can do if we want to avoid deeper activations from converging to zero?
The 5/3 gain in the tanh comes for the average value of tanh^2(x) where x is distributed as a Gaussian, i.e.
I'm at , so haven't finished yet. But something is unclear: what's the point of stacking these layers instead of having just one Linear and one Tanh? Since tanh squashes and afterwards we're diffusing, it seems to me like we're doing accordion-like work unnecessarily. What is the benefit we're getting?
5/3=1.66... is pretty close to the golden ratio 1.61803. Coincidence?
viz #2: backward pass gradient statistics
- Backward pass gradients: Should be similar across layers, signifying balanced gradient flow ().
the fully linear case of no non-linearities
-[-1 prevents shrinking and diffusion in batch normalization.
The reason the gradients of the higer layers have a bigger deviation (in the absence of tanh layer), is that you can write the whole NN as a sum of products, and it is easy to see that each weight of Layer 0 appears in 1 term, of layer 1 in 30 terms, of layer 2 in 3000 terms and so on. Therefore a small change of a weight in higer layers changes the output more.
]Setting gain correctly at
Does anyone know the paper about "analyzing infinitely linear layers"? Andrej mentioned in the video
There is one doubt I have @ and that is regarding the condition p.dim==2, I don't understand why this was done and which parameters it will filter out?
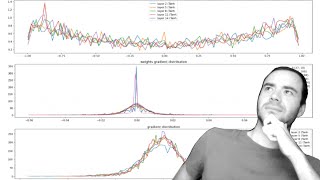
viz #3: parameter activation and gradient statistics
- Parameter weights: Distribution and scale should be monitored for anomalies and asymmetries ().
-[-100 times greater, causing faster training, but it self-corrects with longer training.
"That's problematic because in that simple stochastic gradient setup you would be training this last layer 10x faster with respect to the other layers". Why 10x faster?
]The last layer has gradients
viz #4: update:data ratio over time
on a log scale, indicating a good learning rate and balanced parameter updates ().
did you try using log L2 norm ratio here instead of std? you're using variance as a proxy for how big updates are w.r.t. data values
can someone explain why we divide std of gradient to std of data instead of using mean? Weight update ratio = grad*learning_rate/weight_value. As we have multiple inputs and multiple entries in batch, we could take mean to calculate single value, cannot figure out how std is a better option.
At why do we use standard deviation to calculate update to data ratio?
Why stddev here? Wouldn't we want to use something like the L1-norm? Also, wouldn't we want to log this metric before updating the parameters?
-[-3 on log plot.
]Monitoring update ratio for parameters to ensure efficient training, aiming for -
bringing back batchnorm, looking at the visualizations
summary of the lecture for real this time
]Introduce batch normalization and pytorch modules for neural networks.
]Introduction to diagnostic tools for neural network analysis.
-[-
]Introduction to diagnostic tools in neural networks, active research in initialization and backpropagation, ongoing progress
